【译】Agent 质量白皮书
原文:Agent Quality, Google 作者:Meltem Subasioglu, Turan Bulmus, Wafae Bakkali 发布日期:2025 年 11 月
引言
我们正处于 AI Agent 时代的黎明。从可预测的、基于指令的工具过渡到自主的、目标导向的 AI Agent,这是数十年来软件工程领域最深刻的变革之一。虽然这些 Agent 释放了令人难以置信的能力,但其固有的非确定性使它们变得不可预测,打破了我们传统的质量保证模型。
本白皮书作为应对这一新现实的实用指南,建立在一个简单但激进的原则之上:
Agent 质量是架构支柱,而非最终测试阶段。
本指南建立在三个核心信息之上:
- 轨迹即真相:我们必须超越仅评估最终输出。Agent 质量和安全的真正衡量标准在于其整个决策过程。
- 可观测性是基础:你无法评判看不见的过程。我们详细介绍了可观测性的”三大支柱”——日志、追踪和指标——作为捕获 Agent “思考过程”的基础技术架构。
- 评估是持续循环:我们将这些概念整合为”Agent 质量飞轮”,这是一个将数据转化为可操作洞察的运营手册。该系统使用可扩展的 AI 驱动评估器和不可或缺的人机协同(HITL)判断的混合方式来推动持续改进。
第一章:非确定性世界中的 Agent 质量
为什么 Agent 质量需要新方法
人工智能世界正在全速转型。我们正在从构建执行指令的可预测工具,转向设计能够解释意图、制定计划并执行复杂多步骤动作的自主 Agent。
要理解这种转变,可以将传统软件比作送货卡车,将 AI Agent 比作 F1 赛车。卡车只需要基本检查(“发动机启动了吗?是否按照固定路线行驶?”)。而赛车,就像 AI Agent,是一个复杂的自主系统,其成功取决于动态判断。它的评估不能是简单的检查清单;它需要持续的遥测来判断每个决策的质量——从油耗到制动策略。
传统软件验证问的是:“我们是否正确地构建了产品?“它根据固定规范验证逻辑。现代 AI 评估必须问一个更复杂的问题:“我们是否构建了正确的产品?“这是一个验证过程,在动态和不确定的世界中评估质量、鲁棒性和可信度。
Agent 失败模式
AI Agent 的失败方式不同于传统软件。它们的失败通常不是系统崩溃,而是质量的微妙退化,源于模型权重、训练数据和环境交互的复杂相互作用。这些失败是隐蔽的:系统继续运行,API 调用返回 200 OK,输出看起来合理。但它是根本错误的,在操作上是危险的,并在悄悄侵蚀信任。
| 失败模式 | 描述 | 示例 |
|---|---|---|
| 算法偏见 | Agent 将训练数据中存在的系统性偏见操作化并可能放大,导致不公平或歧视性结果 | 负责风险汇总的金融 Agent 基于有偏见训练数据中发现的邮编过度惩罚贷款申请 |
| 事实幻觉 | Agent 以高置信度产生听起来合理但实际上不正确或虚构的信息 | 研究工具在学术报告中生成高度具体但完全错误的历史日期或地理位置 |
| 性能与概念漂移 | 随着 Agent 交互的真实世界数据(“概念”)发生变化,其性能会随时间退化 | 欺诈检测 Agent 无法发现新的攻击模式 |
| 涌现的非预期行为 | Agent 开发出新颖或意想不到的策略来实现其目标,可能是低效的、无益的或可利用的 | 发现并利用系统规则中的漏洞;与其他机器人进行”代理战争” |
范式转变:从可预测代码到不可预测 Agent
核心技术挑战源于从以模型为中心的 AI 到以系统为中心的 AI 的演变。评估 AI Agent 与评估算法根本不同,因为 Agent 是一个系统。
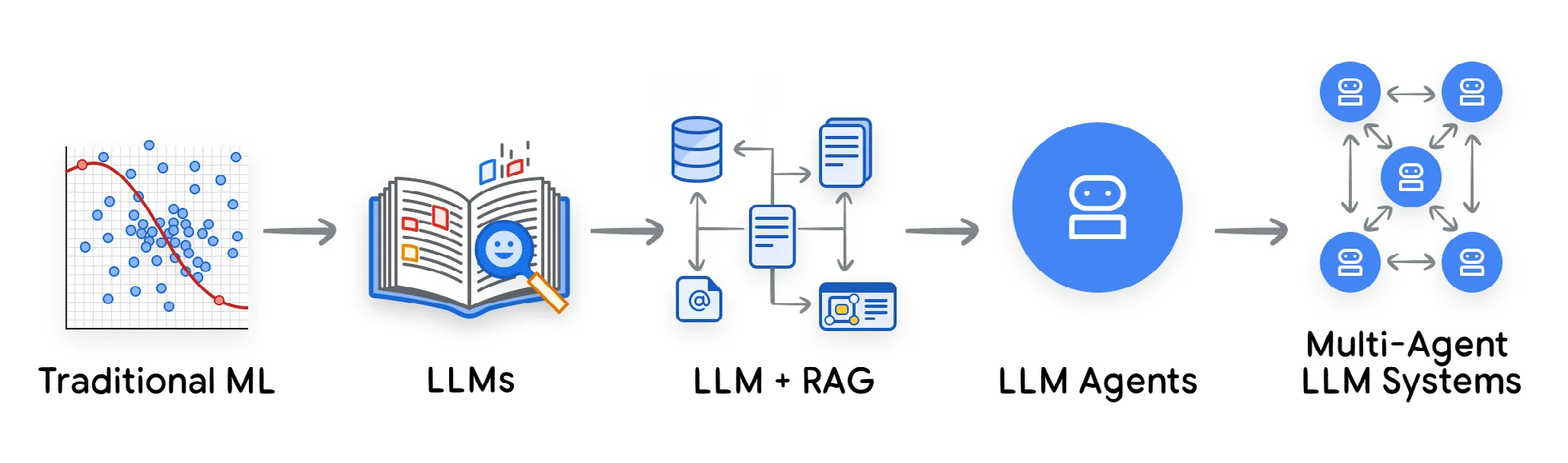
- 传统机器学习:评估回归或分类模型虽然不简单,但是一个定义明确的问题。我们依赖统计指标如精确率、召回率、F1 分数和 RMSE 来对照保留测试集。
- 被动式 LLM:随着生成模型的兴起,我们失去了简单的指标。如何衡量生成段落的”准确性”?输出是概率性的。
- LLM + RAG:下一个飞跃引入了多组件流水线。现在,失败可能发生在 LLM 或检索系统中。
- 主动式 AI Agent:如今,LLM 不再只是文本生成器;它是集成在能够自主行动的复杂系统中的推理”大脑”。这引入了三个核心技术能力:
- 规划与多步骤推理:Agent 将复杂目标分解为多个子任务,创建轨迹(思考 → 行动 → 观察 → 思考…)
- 工具使用与函数调用:Agent 通过 API 和外部工具与真实世界交互
- 记忆:Agent 维护状态,行为会随时间演变
- 多 Agent 系统:当多个主动 Agent 被集成到共享环境中时,会出现系统级涌现现象
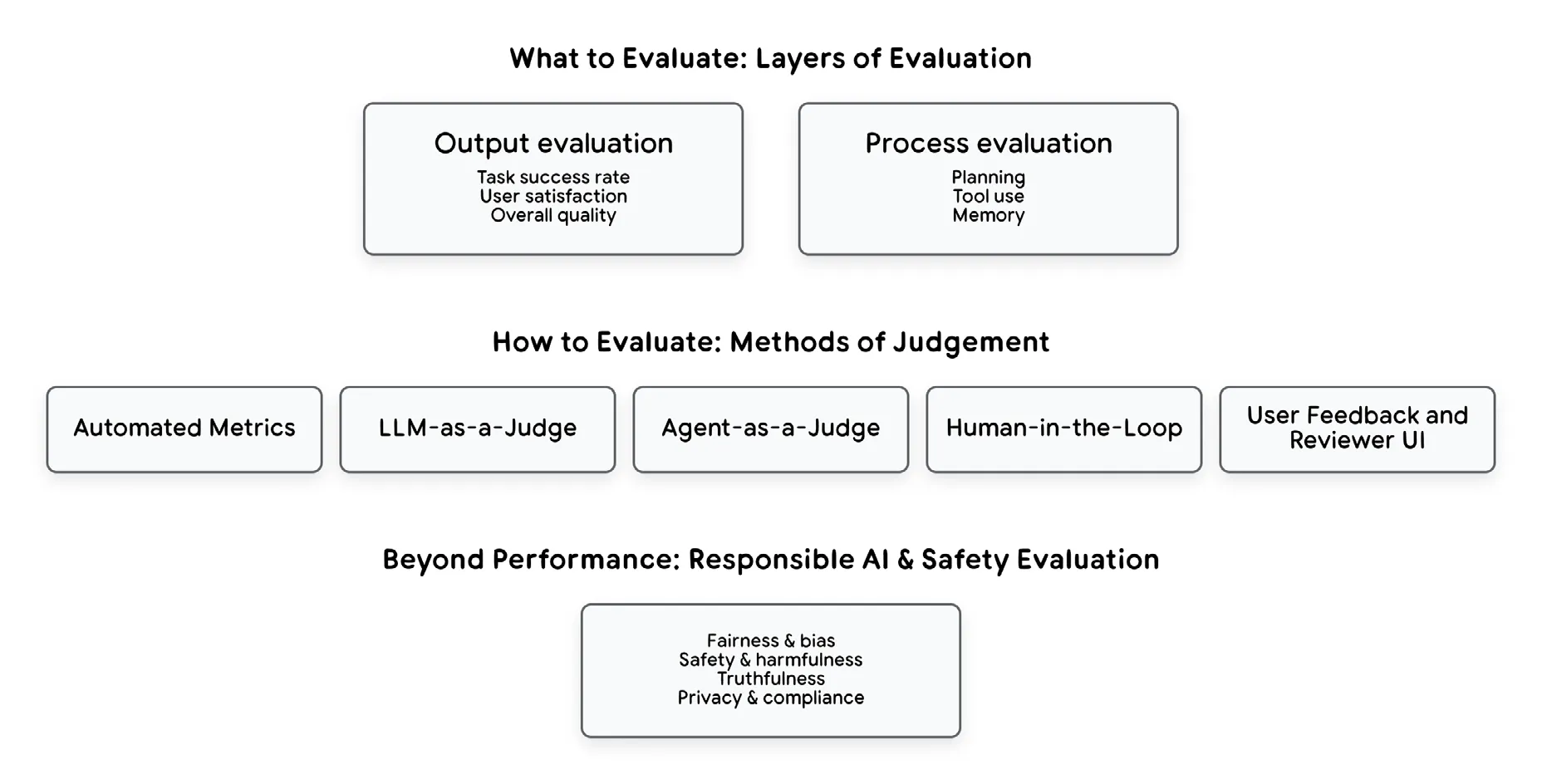
Agent 质量的四大支柱
如果我们不能再依赖简单的准确率指标,并且必须评估整个系统,我们从哪里开始?答案是一种被称为”由外向内”方法的战略转变。

- 有效性(目标达成):Agent 是否成功准确地实现了用户的实际意图?这直接连接到以用户为中心的指标和业务 KPI。
- 效率(运营成本):Agent 是否很好地解决了问题?效率以消耗的资源来衡量:总 token(成本)、墙钟时间(延迟)和轨迹复杂度(总步骤数)。
- 鲁棒性(可靠性):Agent 如何处理逆境和真实世界的混乱?当 API 超时、网站布局改变、数据缺失或用户提供模糊提示时,Agent 是否优雅地失败?
- 安全与对齐(可信度):这是不可妥协的关卡。Agent 是否在其定义的伦理边界和约束内运行?
第二章:Agent 评估的艺术
”由外向内”评估层次结构
为避免迷失在组件级指标的海洋中,评估必须是自上而下的战略过程。我们称之为”由外向内”层次结构。这种方法优先考虑唯一最终重要的指标——真实世界的成功——然后再深入了解该成功发生或未发生的技术细节。
“由外向内”视图:端到端评估(黑盒)
第一个也是最重要的问题是:“Agent 是否有效地实现了用户的目标?”
这个阶段的指标关注整体任务完成:
- 任务成功率:最终输出是否正确、完整并解决了用户的实际问题
- 用户满意度:直接用户反馈分数或客户满意度分数(CSAT)
- 整体质量:准确性或完整性
”由内向外”视图:轨迹评估(玻璃盒)
一旦识别出失败,我们转向”由内向外”视图,系统地评估执行轨迹的每个组件:
- LLM 规划(“思考”):核心推理是否存在问题?失败包括幻觉、无意义响应、上下文污染或重复输出循环
- 工具使用(选择与参数化):Agent 是否调用了错误的工具、未能调用必要的工具、幻觉工具名称或参数
- 工具响应解释(“观察”):Agent 是否正确理解了工具执行的结果
- RAG 性能:检索的信息质量如何
- 轨迹效率和鲁棒性:暴露低效的资源分配,如过多的 API 调用、高延迟或冗余工作
- 多 Agent 动态:Agent 间通信日志,确保 Agent 遵守其定义的角色
评估者:谁来判断以及如何判断
自动化指标
自动化指标提供速度和可重复性:
- 基于字符串的相似度(ROUGE、BLEU)
- 基于嵌入的相似度(BERTScore、余弦相似度)
- 任务特定基准
LLM-as-a-Judge 范式
如何自动化评估定性输出如”这个摘要好吗?“或”这个计划合乎逻辑吗?“答案是使用与我们试图评估的相同技术。LLM-as-a-Judge 范式涉及使用强大的最先进模型来评估另一个 Agent 的输出。
我们为”法官”LLM 提供 Agent 的输出、原始提示、“黄金”答案或参考(如果存在),以及详细的评估标准。
实践提示:优先使用成对比较而非单独评分。让 LLM 在 A 和 B 两个响应之间选择比获得绝对的 1-5 分更可靠。
Agent-as-a-Judge
虽然 LLM 可以对最终响应评分,但 Agent 需要对其推理和行动进行更深入的评估。新兴的 Agent-as-a-Judge 范式使用一个 Agent 来评估另一个 Agent 的完整执行轨迹。关键评估维度包括:
- 计划质量
- 工具使用
- 上下文处理
人机协同(HITL)评估
虽然自动化提供规模,但它难以处理深层主观性和复杂领域知识。HITL 是捕获自动化系统遗漏的关键定性信号和细微判断的必要过程。
HITL 过程涉及几个关键功能:
- 领域专业知识:利用领域专家评估事实正确性
- 解释细微差别:判断定义高质量交互的微妙品质
- 创建”黄金集”:策划综合评估集,定义成功目标
负责任 AI(RAI)与安全评估
评估的最后一个维度不是作为组件运作,而是作为任何生产 Agent 的强制性、不可妥协的关卡:负责任 AI 与安全。一个 100% 有效但造成伤害的 Agent 是完全的失败。
安全评估涉及:
- 系统性红队测试:主动尝试使用对抗性场景破坏 Agent
- 自动过滤器与人工审查:实施技术过滤器捕获策略违规,并与人工审查相结合
- 遵守指南:明确评估 Agent 的输出是否符合预定义的伦理指南和原则
第三章:可观测性——洞察 Agent 的思维
从监控到真正的可观测性
传统软件是快餐厨房的流水线厨师,有固定的食谱卡片。步骤是刚性和确定性的。监控在这个世界里是一个检查清单。
AI Agent 是”神秘盒子”挑战中的美食厨师。厨师被给予一个目标和一篮子食材。没有单一正确的食谱。可观测性是美食评论家评判厨师的方式——不仅品尝最终菜肴,还要理解过程和推理。
可观测性的三大支柱
支柱一:日志——Agent 的日记
日志是可观测性的原子单位。把它们想象成 Agent 日记中带时间戳的条目。每个条目都是关于离散事件的原始、不可变的事实。
有效日志的关键要素:
- 核心信息:提示/响应对、中间推理步骤、结构化工具调用
- 权衡:详细程度 vs 性能:生产环境中需要平衡详细日志与性能开销
// 结构化日志条目示例
2025-07-10 15:26:13,778 - DEBUG - LLM Request:
System Instruction: You roll dice and answer questions...
Contents: {"parts":[{"text":"Roll a 6 sided dice"}],"role":"user"}
Functions: roll_die: {'sides': {'type': 'INTEGER'}}支柱二:追踪——跟随 Agent 的足迹
如果日志是日记条目,追踪就是将它们连接成连贯故事的叙事线索。追踪跟踪单个任务——从初始用户查询到最终答案——将单独的日志(称为 span)缝合成完整的端到端视图。
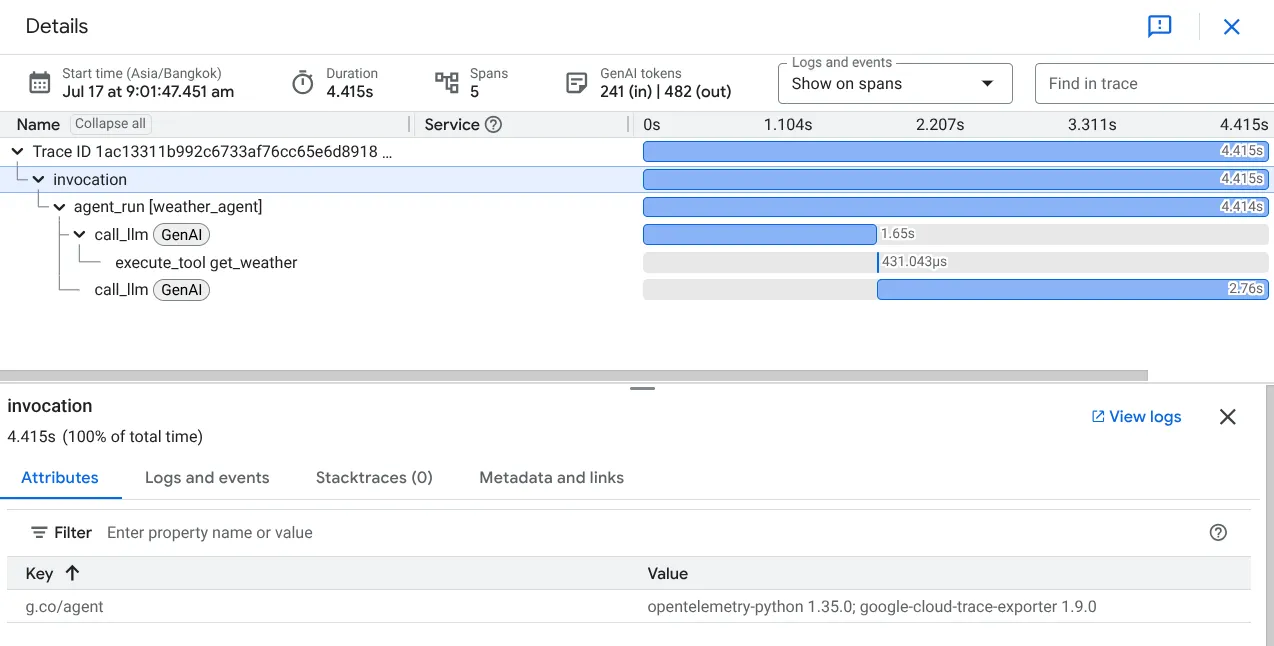
追踪的核心组件:
- Span:追踪中的单个命名操作
- 属性:附加到每个 span 的丰富元数据
- 上下文传播:通过唯一的 trace_id 将 span 链接在一起的”魔法”
支柱三:指标——Agent 的健康报告
指标是量化的、聚合的健康分数,让你立即、一目了然地了解 Agent 的整体性能。
系统指标(运营健康的基础量化测量):
- 延迟(P50/P99)
- 错误率
- 每任务 Token 数
- 任务完成率
质量指标(评估 Agent 的推理和最终输出质量):
- 正确性与准确性
- 轨迹遵守度
- 安全与责任
- 帮助性与相关性
从原始数据到可操作洞察
将可观测性数据转化为实时行动涉及三个关键运营实践:
仪表板与告警:分离系统健康与模型质量
- 运营仪表板(用于系统指标):实时运营健康
- 质量仪表板(用于质量指标):Agent 有效性的细微指标
安全与 PII:保护数据
- 强大的 PII 清洗机制必须是日志管道的集成部分
核心权衡:粒度 vs 开销
- 最佳实践——动态采样:开发环境使用高粒度日志,生产环境实施动态采样
第四章:结论——在自主世界中建立信任
Agent 质量飞轮
伟大的 Agent 不仅要表现出色;还要不断改进。这种持续评估的纪律将一个聪明的演示与企业级系统区分开来。

飞轮的组件如何协同工作:
- 步骤 1:定义质量(目标):质量的四大支柱——有效性、成本效率、安全性和用户信任
- 步骤 2:为可见性进行监测(基础):让 Agent 产生结构化日志和端到端追踪
- 步骤 3:评估过程(引擎):使用可扩展的 LLM-as-a-Judge 系统和 HITL”黄金标准”的混合引擎
- 步骤 4:构建反馈循环(动力):每个生产失败被程序化地转换为”黄金”评估集中的永久回归测试
构建可信 Agent 的三个核心原则
原则一:将评估视为架构支柱,而非最终步骤
记住 F1 赛车的类比:你不会先造一辆 F1 赛车然后再装上传感器。你从第一行代码开始就设计它具有遥测端口。
原则二:轨迹即真相
对于 Agent,最终答案只是长篇故事的最后一句话。Agent 逻辑、安全和效率的真正衡量标准在于其端到端的”思考过程”——轨迹。
原则三:人类是仲裁者
自动化是我们实现规模化的工具;人性是我们真相的来源。对”好”的基本定义、对细微输出的验证以及对安全和公平的最终判断必须锚定在人类价值观上。
未来是 Agentic 的——也是可靠的
我们正处于 Agent 时代的黎明。创造能够推理、规划和行动的 AI 的能力将是我们时代最具变革性的技术转变之一。但强大的能力伴随着深刻的责任——构建值得我们信任的系统。
掌握本白皮书中的概念——可以称之为“评估工程”——是下一波 AI 浪潮的关键竞争差异化因素。继续将 Agent 质量视为事后想法的组织,将陷入“演示精彩但部署失败”的循环中。相比之下,那些投资于这种严格的、架构集成的评估方法的组织,将是那些超越炒作、部署真正具有变革性的企业级 AI 系统的组织。
最终目标不仅仅是构建能工作的 Agent,而是构建被信任的 Agent。而这种信任,正如我们所展示的,不是希望或运气的问题。它是在持续、全面和架构健全的评估的熔炉中锻造的。
参考文献
- Lewis, P. 等 (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Lin, S. 等 (2022). TruthfulQA: Measuring how models mimic human falsehoods
- Li, D. 等 (2024). From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
- Zhuge, M. 等 (2024). Agent-as-a-Judge: Evaluate Agents with Agents
- Wei, J. 等 (2022). Chain-of-thought prompting elicits reasoning in large language models
