如何写一个 AI Agent Skill:从结构到迭代的完整指南
Skill 是 2026 年 Coding Agent 生态里最重要的扩展机制之一。Claude Code、OpenCode、Cursor、Gemini CLI 都支持通过 Skill 给 Agent 注入专项能力——前端设计、TDD 流程、代码评审、浏览器自动化,甚至公众号排版。但多数人停留在”装别人写的 Skill”这一步。这篇文章讲清楚怎么自己写一个,以及怎么用 Skill Creator 把它迭代到好用。
什么是 Skill
Skill 本质上是一份给 AI Agent 的”上岗培训手册”。没有 Skill 的 Agent 是通才——什么都能聊两句,但缺少特定领域的深度知识和标准化流程。装上 Skill 之后,Agent 就变成了某个领域的专家。
打个比方:你招了一个聪明的实习生,他什么都懂一点,但你不会直接让他去做代码评审或操作生产环境。你会给他一份清单:该看什么、该问什么、什么情况下必须停手。Skill 就是这份清单。
不只是 Markdown 文件
一个常见的误解是”Skill 就是一个 Markdown 文件”。实际上,Skill 是一个文件夹,Agent 可以发现、探索并操作其中的内容。一个完整的 Skill 可能长这样:
skill-name/
├── SKILL.md # 必须:主指令文件(<500 行)
├── scripts/ # 可选:可执行脚本,处理确定性任务
├── references/ # 可选:按需加载的参考文档
└── assets/ # 可选:输出时使用的模板、图片等其中 SKILL.md 是唯一必须的文件,其余三个目录按需添加。
Skill 的分类
Anthropic 在《构建 Claude Code 的经验:我们如何使用 Skills》一文中,把内部数百个 Skill 归纳为 8 个类别。这套分类非常实用——在写自己的 Skill 之前,先搞清楚它属于哪一类,能帮你找到正确的设计方向。
库/SDK 类——教 Agent 正确使用某个库或 CLI。通常包含参考代码片段和踩坑点清单。比如内部计费库的边界情况、CLI 工具每个子命令的使用示例、设计系统的组件规范。
验证类——描述如何测试或验证代码是否正常运行。通常与 Playwright、tmux 等外部工具配合。比如在无头浏览器中跑完整的注册到入职流程,或用 Stripe 测试卡驱动结账 UI 并验证发票状态。Anthropic 认为这类 Skill 值得投入一名工程师一整周来打磨。
数据与监控类——连接到数据和监控栈。包含取数脚本、仪表板 ID、常见查询模式。比如”哪些事件需要关联才能看到注册→激活→付费的转化”。
工作流自动化类——把重复流程自动化为一条命令。比如 standup-post 聚合工单、GitHub 活动和 Slack 消息生成每日站报;weekly-recap 把已合并的 PR + 已关闭的工单 + 部署情况格式化为每周回顾。
脚手架类——为特定功能生成框架样板代码。当脚手架有无法单纯靠代码覆盖的自然语言要求时特别有用。比如用你的注解为新服务生成脚手架,或预配置好鉴权和部署的新应用模板。
代码评审类——强制执行代码质量标准。可以包含确定性脚本,也可以作为 Hook 或 GitHub Action 自动运行。比如派出子 Agent 做批判性评审并迭代修复,或强制执行代码风格和测试实践。
Git 与部署类——获取、推送和部署代码。比如 babysit-pr 监控 PR、重试不稳定的 CI、解决合并冲突;deploy-<service> 执行构建→冒烟测试→渐进式流量发布→异常自动回滚。
排查类——接收症状(Slack 讨论串、警报、错误特征码),执行多工具协作调查,生成结构化报告。比如为高流量服务映射症状到工具的查询模式,或根据请求 ID 从所有相关系统提取匹配日志。
好的 Skill 通常能清晰地归入其中一类。如果一个 Skill 横跨多个类别,往往意味着它需要被拆分。
Skill 是怎么被触发的
理解触发机制对写好 Skill 很关键。当 Agent 启动会话时,它会加载所有可用 Skill 的 name + description(也就是 SKILL.md 开头 YAML frontmatter 里的两个字段)。Agent 根据用户输入的内容,判断”有没有哪个 Skill 能帮上忙”,如果匹配就加载那个 Skill 的完整内容。
这意味着:
- description 不是摘要,而是触发条件——它决定了 Skill 在什么情况下会被调用
- SKILL.md 正文在触发之后才会被读取——所以”什么时候用”的信息必须放在 description 里,不能放在正文
Skill 的核心结构
一个 SKILL.md 文件由两部分组成:YAML frontmatter 和 Markdown 正文。
Frontmatter
---
name: my-skill
description: 什么时候触发、做什么事。包含所有触发关键词。
---name 和 description 是必填字段。description 最为关键,后面会单独讲怎么写好它。
正文结构
没有强制格式,但好的 Skill 通常包含这几个部分:
1. Iron Law(铁律)
放在最开头,用一句话阻止 Agent 最可能犯的错误。
比如 systematic-debugging这个 skill 的铁律是:
NO FIXES WITHOUT ROOT CAUSE INVESTIGATION FIRSTtest-driven-development这个 skill 的铁律是:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST铁律不是口号,是硬约束。Agent 会认真对待这类全大写的规则。
2. 工作流清单
用 Markdown checklist 定义执行步骤,让 Agent 可以逐项跟踪进度:
## Workflow
- [ ] Step 1: 分析输入
- [ ] Step 2: 执行操作
- [ ] Step 3: 验证结果
- [ ] Step 4: 输出报告可以用 ⚠️ REQUIRED 标记不可跳过的步骤,用 ⛔ BLOCKING 标记必须先完成的前置条件。
3. 确认门控
在危险操作前强制 Agent 暂停,等用户确认:
### Before applying changes
STOP and present findings to the user.
Do NOT implement fixes unless the user explicitly asks.这在代码评审、文件删除、生产环境操作等场景里非常重要。
4. 反面模式
明确列出”不要做什么”,比”要做什么”更有效。Agent 默认行为里的坏习惯,需要你主动拦截:
## Anti-Patterns
- ❌ 不要猜测式修复(先定位根因)
- ❌ 不要使用 `as any` 来绕过类型错误
- ❌ 不要删除失败的测试来"让测试通过"5. 参考文档的渐进式加载
如果 Skill 内容太长(超过 500 行),把详细内容拆到 references/ 目录下,在 SKILL.md 里按需引用:
### Security scan
→ Load `references/security-checklist.md` for coverage.比如 code-review-expert这个 skill 的结构如下:
code-review-expert/
├── SKILL.md # 主文件,156 行
├── references/
│ ├── solid-checklist.md # SOLID 原则清单
│ ├── security-checklist.md # 安全检查清单
│ ├── code-quality-checklist.md # 代码质量清单
│ └── removal-plan.md # 删除计划模板
└── agents/
└── agent.yamlAgent 不会一次性把所有参考文档加载到上下文里,而是执行到对应步骤时才去读取。这种渐进式加载(Progressive Disclosure)对控制 token 用量很关键。
frontend-design 也是同样的思路——主文件不到 150 行,但 reference/ 目录下有排版、色彩、动效、响应式设计等 7 个专题文档。
从零开始写一个 Skill
以写一个”代码评审”Skill 为例,走一遍完整流程。
Step 1:明确目标
先回答三个问题:
- 解决什么问题? Agent 默认的代码评审太泛泛,缺少结构化流程和安全扫描
- 用户会怎么说? “帮我 review 一下代码”、“看看这个 PR”、“code review”
- 好的输出长什么样? 按 P0-P3 分级的结构化报告,不自动改代码
Step 2:创建文件
mkdir -p ~/.agents/skills/my-code-review
touch ~/.agents/skills/my-code-review/SKILL.mdStep 3:写 Frontmatter
---
name: my-code-review
description: Expert code review of current git changes. Detects architecture
issues, security risks, and proposes actionable improvements. Use when the
user asks to review code, check a PR, do a code review, or wants feedback
on their changes. Also triggers on "review my code", "look at this diff",
"check for issues".
---注意 description 里包含了各种可能的触发短语。Skill 的触发率偏低是已知问题——description 写得”激进”一点,多覆盖一些表述方式,效果会更好。
Step 4:写正文
# Code Review
## Iron Law
Review only. Do NOT implement changes unless the user explicitly asks.
## Workflow
- [ ] 1. Scope changes: `git diff --stat` + `git diff`
- [ ] 2. Architecture review: check SOLID principles
- [ ] 3. Security scan: injection, auth gaps, secret leakage
- [ ] 4. Code quality: error handling, performance, edge cases
- [ ] 5. Output findings by severity (P0 > P1 > P2 > P3)
- [ ] 6. STOP. Present to user. Do not auto-fix.
## Severity
| Level | Name | Action |
|-------|------|--------|
| P0 | Critical | Must block merge |
| P1 | High | Should fix before merge |
| P2 | Medium | Fix or create follow-up |
| P3 | Low | Optional |
## Anti-Patterns
- ❌ Don't review without reading the full diff first
- ❌ Don't auto-fix issues without user confirmation
- ❌ Don't ignore test files — they have bugs tooStep 5:测试
最简单的测试方式:在 Agent 里直接用。改几行代码,然后让 Agent review,看它有没有按你的流程走。
如果没有被触发——回去改 description,加更多触发关键词。 如果流程不对——调整正文里的步骤顺序和约束。
用 Skill Creator 迭代改进
手动写完初稿之后,就可以请 Skill Creator 出场了。它是一个专门用来创建和迭代改进 Skill 的 Skill——没错,这是一个”写 Skill 的 Skill”。
Skill Creator 是什么
Skill Creator 提供了一套完整的 Skill 开发工作流:
- 起草:帮你明确意图、编写 SKILL.md
- 测试:自动生成测试用例,并行运行”有 Skill”和”无 Skill”两组对照
- 评估:量化基准 + 人工审查,找到需要改进的地方
- 迭代:根据反馈修改 Skill,重新测试,循环直到满意
- 优化描述:自动化调优 description 的触发准确率
核心流程
1. 启动
在 Agent 中说出类似这样的话:
我想创建一个 Skill,用来 [做某件事]或者:
帮我改进这个 Skill:[Skill 路径]Skill Creator 会引导你回答几个问题:这个 Skill 要做什么、什么时候触发、期望输出是什么格式。
2. 生成测试用例
Skill Creator 会为你的 Skill 生成 2-3 个真实的测试 Prompt,保存到 evals/evals.json:
{
"skill_name": "my-code-review",
"evals": [
{
"id": 1,
"prompt": "Review the changes in my current branch",
"expected_output": "Structured review with severity levels"
},
{
"id": 2,
"prompt": "Look at this diff and tell me if there are security issues",
"expected_output": "Security-focused review highlighting vulnerabilities"
}
]
}你可以调整这些测试用例,然后 Skill Creator 会同时运行两组:
- 有 Skill 组:Agent 带着你的 Skill 去执行任务
- 无 Skill 组(基线):Agent 不带任何 Skill 执行同样的任务
3. 量化评估 + 人工审查
测试跑完后,Skill Creator 会:
- 对每个测试用例进行量化打分(断言通过率、耗时、token 用量)
- 生成一个浏览器端的评审界面,让你直接对比”有 Skill”和”无 Skill”的输出差异
- 你在界面上逐个查看输出,留下反馈(“这里少了安全扫描”、“这个格式不对”)
评审界面有两个 Tab:
- Outputs:逐个查看测试用例的输出,留下反馈
- Benchmark:量化对比——通过率、耗时、token 用量的均值和标准差
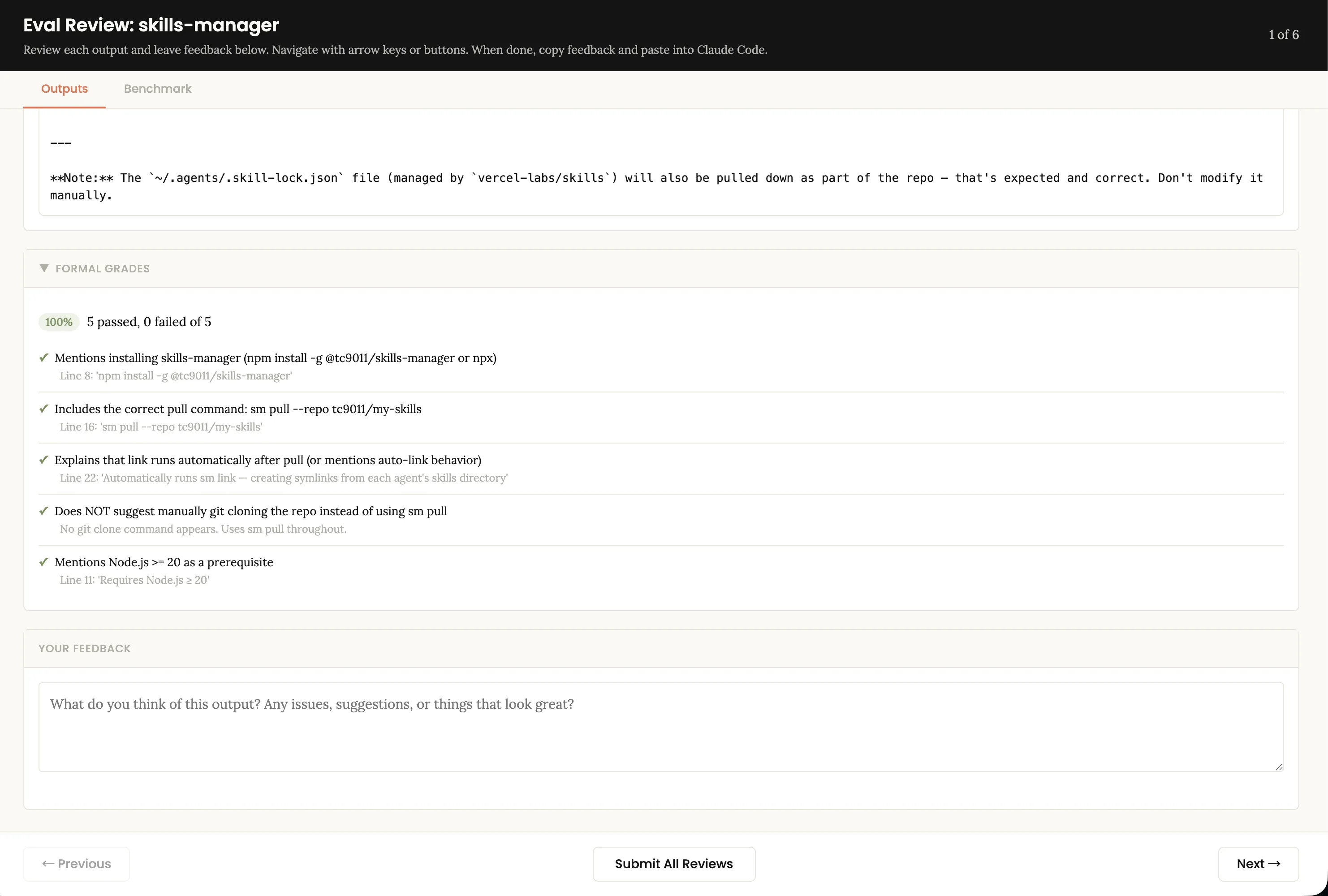
4. 迭代改进
Skill Creator 读取你的反馈后,会修改 SKILL.md,然后重新运行所有测试。新一轮的评审界面会同时展示上一轮的输出和反馈,方便你看到改进效果。
这个循环一直持续到:
- 你对所有输出满意
- 反馈全部为空(都没问题了)
- 改进幅度趋于零
5. 优化 Description
Skill 本身满意之后,还可以单独优化 description 的触发准确率。Skill Creator 会:
- 生成 20 个测试查询——一半应该触发,一半不应该触发
- 让你在浏览器界面中审核这些查询
- 自动跑 5 轮优化,在训练集和测试集上分别评估,选出最佳 description
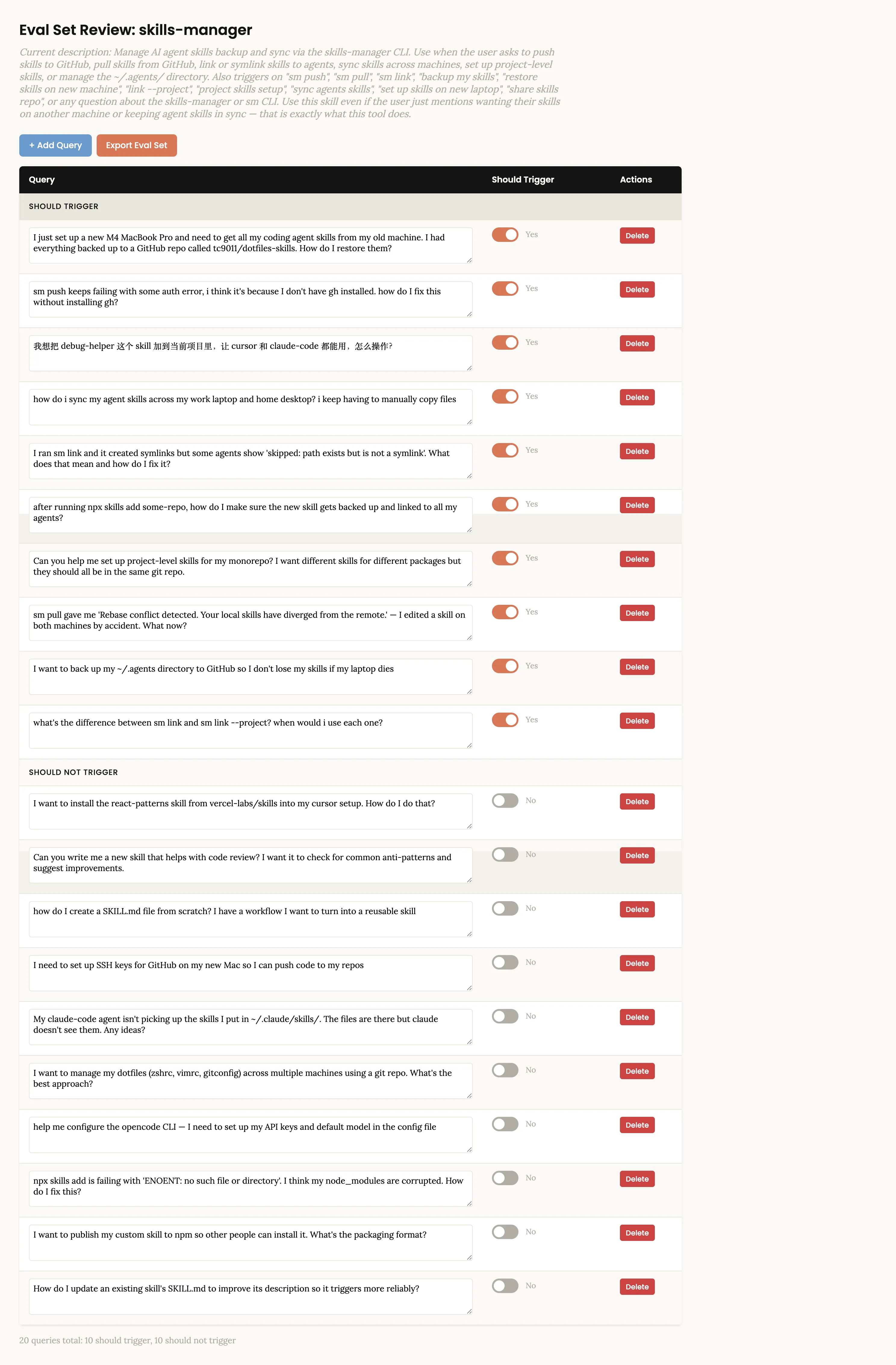
这一步能显著提升 Skill 的自动触发率。很多 Skill 写得很好但就是不触发,问题往往出在 description 上。
改进 Skill 的关键原则
Skill Creator 在迭代中遵循这几个原则,手动改进时也值得参考:
1. 从反馈中泛化,而非针对特定测试用例打补丁
Skill 是要被使用无数次的。如果某个修改只为了让第 2 个测试用例通过,但对其他场景没帮助甚至有害,那就是过拟合。
2. 保持精简
每一行都要能证明它提升了输出质量。如果删掉某段话后效果没变差,就删掉它。
3. 解释为什么,而非只说做什么
现在的 LLM 足够聪明,给它理由比给它死规则更有效。与其写 ALWAYS use P0-P3 severity,不如解释为什么分级很重要——它让评审结果可操作,P0 代表必须阻止合并的问题,P3 是锦上添花。
4. 把重复出现的工作抽成脚本
如果每次测试运行时 Agent 都独立写了类似的辅助脚本,说明这个操作应该被提取到 scripts/ 目录下。写一次,所有后续调用直接复用。
进阶技巧
用脚本处理确定性任务
webapp-testing 这个 Skill 里包含了一个 scripts/with_server.py,用来管理测试服务器的生命周期。SKILL.md 里只告诉 Agent 怎么调用它,不需要 Agent 理解脚本的实现细节:
**Always run scripts with `--help` first** to see usage.
DO NOT read the source until you find that a customized solution
is absolutely necessary.脚本不会被加载到上下文窗口里——它们存在的目的是被执行,而不是被阅读。这节省了大量 token。
把 Skill 当成记忆载体
Skill 可以在目录内存储数据来实现某种形式的”记忆”。比如一个 standup Skill 可以在 standups.log 里记录每次生成的站报,下次运行时 Agent 读取历史,自动识别”从上次到现在有什么变化”。
数据可以存在简单的文本日志里,也可以存在 SQLite 数据库里,取决于复杂度。
用配置文件存储用户偏好
如果 Skill 需要根据用户环境做不同处理(比如发站报到哪个 Slack 频道),可以在 Skill 目录下存一个 config.json。第一次使用时 Agent 询问用户,之后直接读取配置。
多 Skill 组合
Skill 之间可以引用。blog-to-wechat-pipeline 就是一个典型——它自身不做翻译、不做公众号排版、不做封面生成,而是在不同阶段调用 baoyu-translate、wechat-md、baoyu-cover-image 这三个独立的 Skill。单独使用时各自独立,组合使用时串成流水线。
Description 的”关键词轰炸”
Description 是 Skill 的广告牌。Agent 只会看 description 来决定是否触发,所以你要把所有可能的触发表述都塞进去。看看 blog-to-wechat-pipeline 的 description:
Triggers on: ‘转公众号格式并配图’, ‘公众号排版+封面’, ‘blog-to-wechat-pipeline’, ‘翻译后发公众号’, ‘做成公众号发布素材’, ‘和上面一样的流程’, ‘走一下公众号流程’, ‘翻译成中文放进blog’, ‘把这个链接翻译发公众号’
中文、英文、口语化表达、缩写——全覆盖。这就是 Skill Forge 所说的”keyword bombing”技巧。
总结
写一个 Skill 的核心步骤:
- 搞清楚要解决什么问题——Agent 默认做不好的事
- 写好 description——它是触发的关键,不是摘要
- 设定铁律——阻止 Agent 最可能犯的错误
- 定义工作流——可跟踪的 checklist,关键节点设门控
- 列出反面模式——明确”不要做什么”
- 拆分参考文档——主文件控制在 500 行内,细节按需加载
- 用 Skill Creator 迭代——测试、评估、改进,直到满意
- 优化 description——自动化调优触发准确率
好的 Skill 不需要一次写对。先有一个能用的版本,在真实使用中发现问题,不断迭代——这正是 Skill Creator 存在的意义。
# 装一个试试
npx skills add <skill-name>
# 或者从零开始
mkdir -p ~/.agents/skills/my-skill
# 然后开始写你的 SKILL.md